Talk/Demo: Big Geospatial Data with Open-source Tech (Vectors, Rasters & Map-matching)
Summary
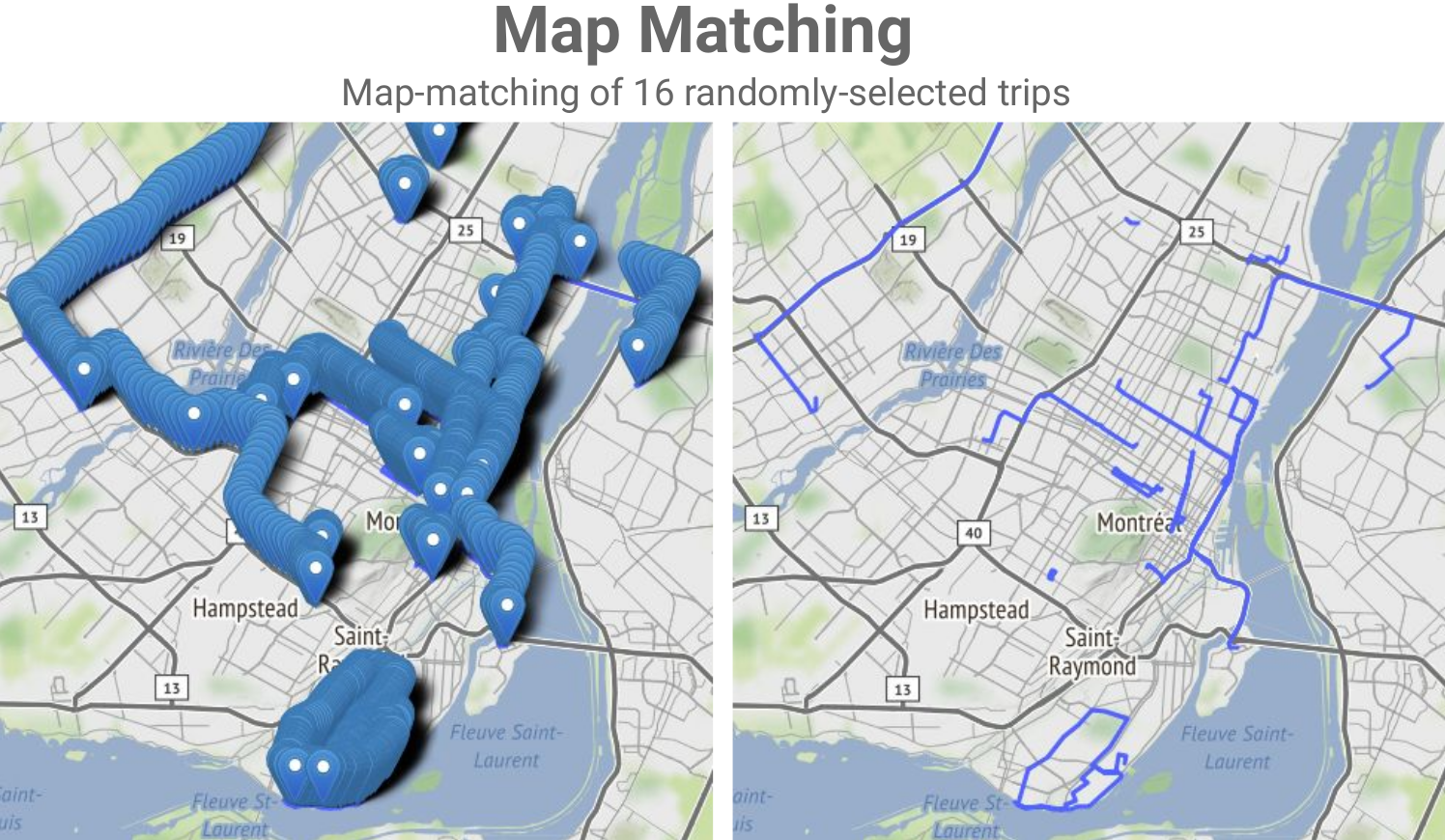
Geospatial datasets (i.e. geocoded data points) are everywhere nowadays and often add enormous value to data analytics/mining and machine learning projects. In this new era of Big Data, libraries and engines such as GeoPandas, PostGIS and the equivalent products in the commercial space often fall short and cannot scale up sufficiently to let us tap into the Big Data that is being collected in many use cases and by many organizations. In this talk/demo, we explore free, open-source, Big Data-ready technologies and workflows like GeoMesa, GeoPySpark and OSRM-on-Spark and show how to use these Apache Spark-based tech/workflows for key geospatial operations and use cases. We start by introducing GeoMesa and demo-ing how it can be used to ingest Big Geospatial Data and perform operations on vectors. Next, we briefly introduce GeoPySpark, the Python interface to Geotrellis, for performing operations on rasters. At the end, we turn to map-matching which is the process of associating names to geocoded data points from an underlying network (e.g., determining which street a particular GPS point should be associated with). We describe and demo how we can combine OSRM with Spark to do scalable map-matching on Big Data and therefore open up a lot of possibilities for advanced data mining and machine learning projects.