Summary
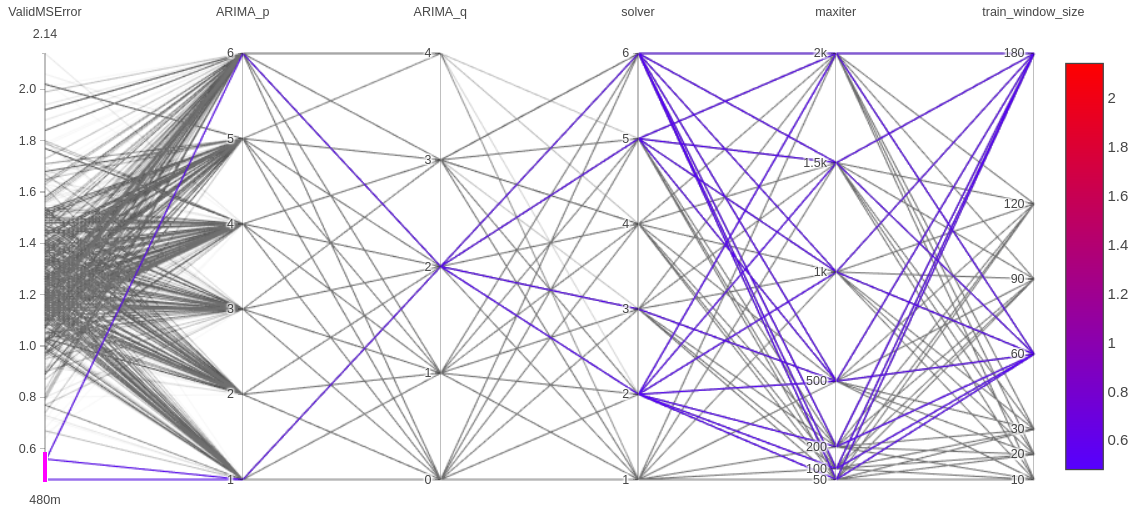
Apache Spark is the state-of-the-art distributed processing, analytics and ML engine and we are presenting and demo-ing two interesting ways one can use Spark in ML projects: 1) we use Spark to distribute the grid-search optimization of a generic ML model (from a regular, single-machine ML library). We show how Spark can distribute processing tasks over the CPU cores of a cluster which gives a near-linear speedup and lowers processing times; hence it facilitates the exploration of a much larger space to find the optimal hyperparameters for the ML model. This use case is suitable when the projects do not involve Big Data and we use Big Data technologies, i.e., Spark, for the purpose of speeding up the processing of tasks; 2) we demonstrate how to train an example model using the ML lib of Spark itself and how to serve the model with MLeap, a production-quality, low-latency serving engine. This second use case/workflow is suitable when projects do involve Big Data.